Fourier regression model to generate monthly to daily temperature data
1 Introduction
In the sphere of meteorology, the significance of statistical models in comprehending and forecasting diverse weather patterns is incontestable. Within this context, the Fourier regression model has emerged as a formidable asset, specifically in generating daily time series from monthly temperature data (Wilks, 1998). The model lays a robust foundation for simulating temperature patterns, yielding crucial insights that are indispensable for weather prediction, climate change studies, and managing water resources.
The Fourier regression model has been proven to be a highly effective tool for generating daily time series from monthly temperature data, enhancing our understanding and prediction capabilities in weather forecasting, climate change studies, and water resource management. This model’s unique ability to incorporate historical context allows it to capture intricate dependencies and transitions in temperature data, which are crucial in understanding temperature patterns.
By applying Fourier series, it is possible to reduce the number of parameters involved in the process, thereby simplifying complex calculations and making the model more efficient. Moreover, the Fourier regression model can seamlessly replace missing values and handle anomalies, which are often challenges in data analysis. This enables more accurate simulations and predictions, making it a vital tool in fields such as agriculture and urban planning.
The Fourier regression model’s success in generating daily time series from monthly temperature data not only contributes to our understanding of weather patterns but also provides practical solutions for real-world challenges, making it a powerful instrument in various domains.
2 Data
Over the past three decades, Bogor’s climate has remained relatively consistent. The city experiences an average annual temperature of around 26 °Celsius. The temperature varies little throughout the year, with the warmest month averaging around 27 °Celsius and the coolest month averaging around 25 °Celsius.
Daily temperature data of Bogor Climatological Station from 1984-2021 were used in this analysis, downloaded from BMKG Data Online in *.xlsx format. The file then manipulated by remove the logo and unnecessary text, aggregated into monthly, leaving only two columns, namely date in column A and temperature in column B for the header with the format extending downwards, and save as *.csv format.
The final input file is accessible via this link: https://drive.google.com/file/d/1vKT5ekDnqahkG6um5wIm-ZfhExqZTAm8/view?usp=sharing
3 Methods
This exercise focuses on the Fourier regression model as a tool for generating daily temperature data from monthly time series (Boer, 1999).
Fourier series can also be employed to generate other climate data. McCaskill (1990a) utilized Fourier series regression, incorporating rainfall events to generate pan evaporation data, maximum and minimum air temperature, and daily radiation intensity (P(i)).
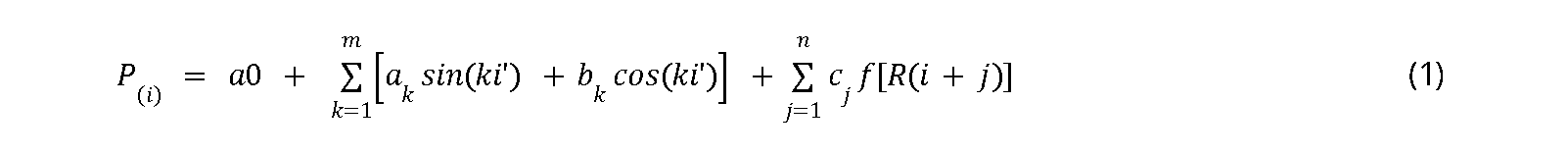
where \(f\) represents a rain function, \(R(i+j)\) is a rain event on day \((i+j)\), and \(c_j\), \(l\), and \(n\) are determined through regression analysis. In the context of Australia, the incorporation of rain events in the Fourier series function did not exert a significant impact, although it substantially reduced the error level of the estimated value (McCaskill, 1990a).
In the above equation 1, the effect of rainfall events is assumed to be additive. However, for certain regions, this rainfall event impact could be multiplicative.
In many cases, climate data is generally presented as monthly data, making analysis requiring daily data difficult to execute. Fourier series regression can also be used to generate daily climate data from average monthly climate data (Epstein, 1991). The equation is written as follows:
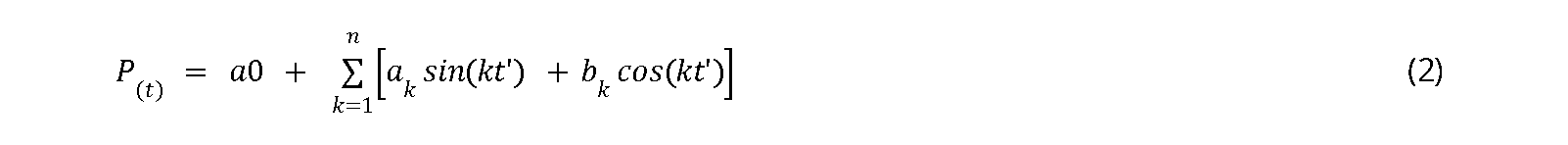
where \(t' = \frac{2\pi t}{12}\), and \(t\) is the month. This equation assumes an equal number of days in each month, which is not the case in reality. Therefore, to adjust it, the value of \(t\) in the above equation is changed as the \(m\)-th day for the \(T\)-th month so that the value \(t = (T-0.5)+\frac{(m-0.5)}{D}\), where \(D\) is the number of days in month \(T\). The use of equation 2 to create fitting lines for daily data is highly effective. The fitting lines composed from daily data and those derived from monthly data almost overlap.
For simulation purposes, an error component, \(e(i)\), which has a normal distribution with a mean of 0 and a variance of \(s^2\) is typically included. Thus, the data series generated by each simulation will differ but still reflect the seasonal diversity of data. Errors in climate data simulation models often autocorrelate. Therefore, the error component can be modeled using a k-th order autocorrelation function (Wannacott and Wannacott, 1987), which is:
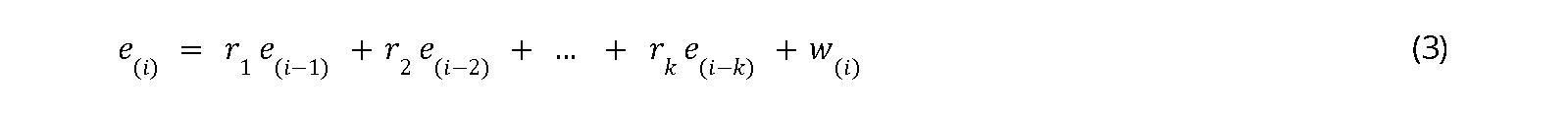
where \(r\) is the correlation value and \(w(i)\) is the random error (white noise). The simplest autocorrelation error function linearly connects the error on day \(i\) with the error on day \(i-1\) plus the random error on day \(i\) (first-order autocorrelation function), namely:

Therefore, if the value of \(r\) is positive, the error on day \(i\) tends to increase if the error on the previous day was high, and vice versa. Practically, the value of \(r\) is always less than one, but its magnitude is unknown.
4 Implementation
In the implementation phase of this analysis, we utilized Python and the Pandas, Numpy and Matplotlib library to develop a Fourier regression model to generate daily time series from monthly temperature data.
4.1 How-to?
The step-by-step guide for the model is readily accessible in Google Colab, an ideal platform for data analysis and machine learning. This comprehensive how-to guide explains the entire process, starting with reshaping the data to ensure compatibility with the model, and aggregate calculation from daily to monthly, assigning monthly data across the corresponding days of the month, Fourier Series Modeling and Coefficient Extraction, Temperature estimation using Fourier Coefficients, Autocorrelated Error Calculation and Final estimates adjusted temperature..
4.1.1 Reshape the data
The first step in our analysis involves pre-processing and reshaping the data to fit the requirements of the subsequent statistical modeling. Our raw temperature data, originally in a CSV file, consists of daily temperature readings recorded over several years. In this data, dates are represented in a ‘YYYY-MM-DD’ format. However, for our analysis, we require the ‘day of the year’ and the ‘year’ as separate variables.
We start by loading the data into a Pandas DataFrame. Next, we convert the ‘date’ column into a datetime format using the pd.to_datetime() function, which facilitates date-specific manipulations. This allows us to extract the ‘day of the year’ and the ‘year’ information from each date and store these in new columns titled ‘dayofyear’ and ‘year’, respectively.
Since we have multiple temperature readings per day, we average these readings for each day of the year across all years. We do this by grouping the data by ‘dayofyear’ and ‘year’, and then calculating the mean temperature for each group using the groupby() and mean() functions.
However, this leaves us with a long format DataFrame, where each row represents a day of a particular year. For easier visualization and modeling, we convert this into a wide format DataFrame, where each column represents a year and each row represents a day of the year. This transformation is performed using the unstack() function.
Lastly, we reset the DataFrame index for neatness and compatibility with future operations. The resulting DataFrame is saved into a new CSV file. This reshaping of data forms the foundation for our Fourier regression model and helps ensure accuracy and efficiency in the subsequent analysis.
Above code will produce output previews like below.
Table 1. Reshape data from long to wide format
4.1.2 Daily to Monthly
In addition to the daily analysis, we decided to explore the temperature trends on a monthly basis. The process for reshaping the data for monthly temperature averages mirrors the daily approach.
First, we load the raw temperature data from a CSV file into a Pandas DataFrame and convert the ‘date’ column to a datetime format. With the datetime format, we’re able to extract the ‘month’ and ‘year’ from each date, creating new columns for each.
As with the daily analysis, we handle multiple temperature readings per day by averaging these for each month of each year. We achieve this by grouping the data by ‘month’ and ‘year’, then calculating the mean temperature for each group.
To facilitate further analysis and visualization, we convert this long format DataFrame to a wide format DataFrame, with each column representing a year and each row representing a month. This is done using the unstack() function.
After resetting the DataFrame index for better data structure, we save the resulting DataFrame into a new CSV file. This CSV file contains average monthly temperatures over the years and will be useful for understanding broader temperature trends and providing context to our Fourier regression model.
Above code will produce output previews like below.
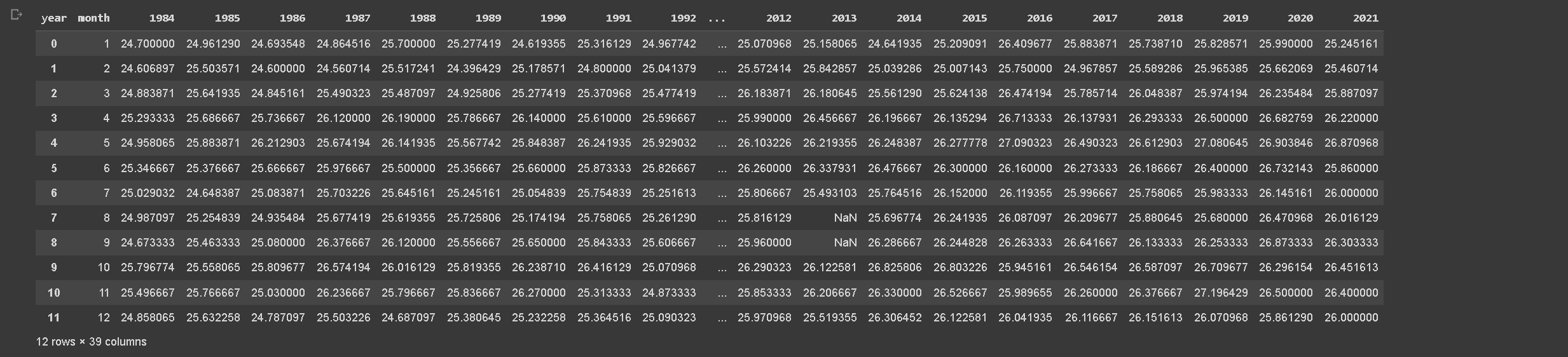
Table 2. Monthly average of temperature
4.1.3 Assigning monthly data into across the corresponding days of the month
In order to prepare our dataset for Fourier regression modeling, we need to map the average monthly temperature values to their corresponding days of the year. This step is crucial as it enables the creation of a continuous time series from the previously calculated monthly averages.
We begin this process by defining the number of days in each month, differentiating between leap and non-leap years. Then, we create a new DataFrame, dayofyear_df, with a ‘dayofyear’ column that sequentially enumerates each day of the year from 1 to 366. A binary ‘leap’ column is also added to indicate if the day corresponds to a leap year.
To map the ‘dayofyear’ to the corresponding month, we create a ‘month’ column using np.repeat() to repeat the month index according to the number of days in each month. This column is then adjusted for non-leap years.
The average monthly temperatures, stored in monthly_avg_df, are merged with the dayofyear_df DataFrame, repeating each monthly average across the corresponding days of the month. As a result, we obtain a DataFrame with daily granularity, which contains the corresponding average monthly temperature for each day.
We then handle the 366th day of non-leap years, setting the temperature to NaN, as it doesn’t exist in those years.
Finally, we remove the unnecessary ‘month’ and ‘leap’ columns, reset the index, and save this DataFrame into a new CSV file. This final, reshaped DataFrame serves as our input for the Fourier regression modeling, enabling us to predict temperatures at a daily level from average monthly temperatures.
Above code will produce output previews like below.
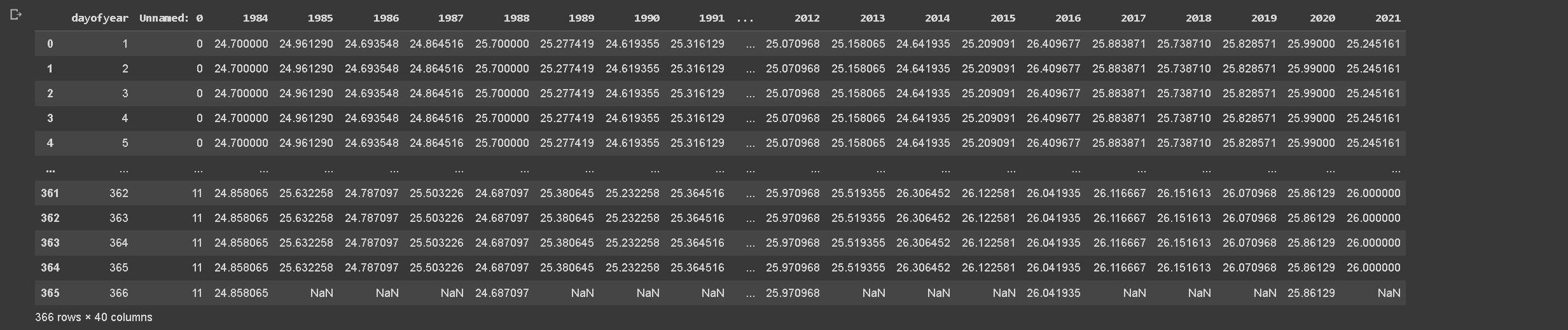
Table 3. Assigning monthly data into daily
4.1.4 Fourier series modeling and coefficient extraction
The next step in the analysis process involves fitting a Fourier series to our daily temperature data. The Fourier series is a mathematical tool used for analyzing periodic functions, making it suitable for modeling periodic patterns in weather data like temperature.
To begin, we first load the reshaped DataFrame containing the daily average temperatures. Next, we define a Fourier function, specifying the form it should take. The function is expressed in terms of trigonometric terms (cosine and sine functions) and includes coefficients that we aim to estimate (a0, a1, b1, a2, b2).
To perform this estimation, we iterate over each year in the DataFrame. For each year, we calculate new variables ‘T’, ‘m’, ‘D’, and ‘t’. These variables represent respectively the month, the day of the month, the number of days in the month, and a transformed time index (where each month is considered as a unit time interval). We exclude data points with NaN or infinite values.
We then utilize the curve_fit function from the scipy.optimize module to fit the Fourier function to the temperature data for each year. This function returns the optimal values for the coefficients a0, a1, b1, a2, and b2 that best fit the data.
In cases where there’s insufficient data to fit the Fourier series, we handle the errors and assign NaN values to the coefficients for that year.
Once we obtain the coefficients for each year, we save this data into a new CSV file. This file will then be used to generate our Fourier regression model and perform temperature estimation. The generated Fourier coefficients provide insights into the amplitude and phase of the cyclical patterns in the temperature data.
Above code will produce output previews like below.

Table 4. Fourier coefficient
4.1.5 Temperature estimation using Fourier coefficient
Having determined the coefficients of the Fourier series for each year, we can now use these coefficients to generate temperature estimates. This step entails constructing a time series model for the daily temperatures based on the Fourier series.
We start by loading the DataFrame that contains the Fourier coefficients for each year. These coefficients were calculated in the previous step and are used to define the form of the Fourier series for each year.
Our next task is to create a new DataFrame, ‘temp_estimates’, to store our estimated temperatures. This DataFrame is initially populated with a ‘dayofyear’ column, containing each day of the year (from 1 to 367).
We then iterate over each year in our coefficients DataFrame. For each year, we create a separate DataFrame ‘year_df’ and calculate the transformed time index ‘t’ just as we did when fitting the Fourier series. This time index is used as the input to our Fourier function.
Next, we use our Fourier function, along with the coefficients for the current year, to calculate the estimated temperature for each day of that year. These estimated temperatures are then added as a new column in the ‘year_df’ DataFrame, with the column name being the current year.
We repeat this process for all years in our dataset, merging the temperature estimates for each year into the ‘temp_estimates’ DataFrame.
Finally, we save these temperature estimates to a new CSV file. The end result of this process is a DataFrame that provides a day-by-day estimate of the temperature for each year based on the Fourier regression model. These estimates serve as the basis for our subsequent analysis and allow us to visualize and quantify the cyclical patterns present in the temperature data.
Above code will produce output previews like below.
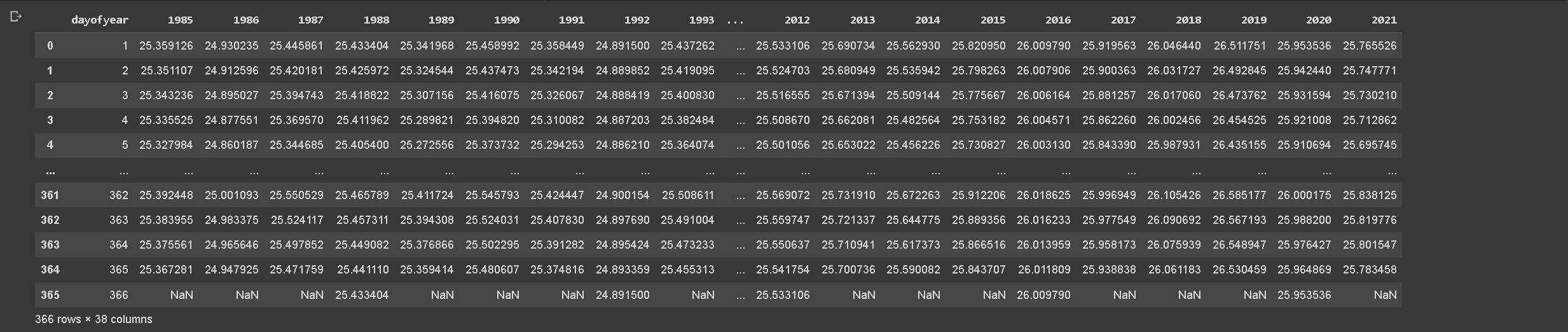
Table 5. Temperature estimates
4.1.6 Autocorrelated error calculation
This code calculates the autocorrelated error between the observed temperature and the estimated temperature from the Fourier model for each year, and stores the errors in a dataframe.
Firstly, we load the wide-format data and the estimated temperature data. Then, we specify an autocorrelation factor (r), which is a parameter that describes the correlation between values of the error at different points in time.
We loop over each year from 1986 to 2022, and for each year we:
Calculate the difference between the observed and estimated temperatures to get the error.
Generate a sequence of random numbers from a normal distribution, called white noise.
Compute the autocorrelated error. The error for the first day is simply the white noise, and for each subsequent day, the error is the autocorrelation factor multiplied by the previous day’s error, plus the white noise for that day.
Finally, we create a DataFrame from the dictionary of autocorrelated errors, and save it to a CSV file.
This autocorrelated error represents the error in our model’s estimate that cannot be explained by the model itself, but rather depends on previous errors. This could be due to factors that we did not include in our model, such as atmospheric conditions or climate change. By including this autocorrelation in our analysis, we can better understand and model these unexplained variations in temperature.
Above code will produce output previews like below.
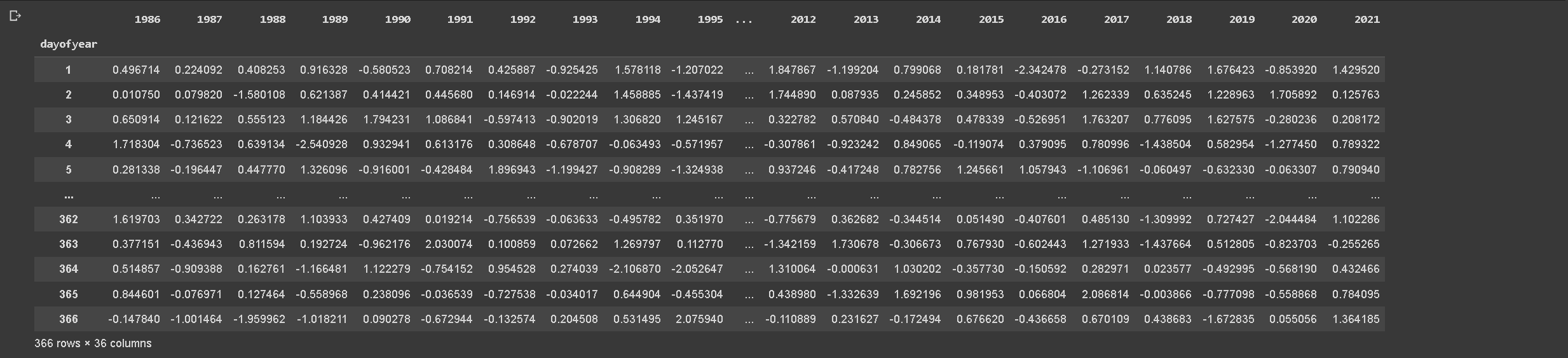
Table 6. Autocorrelated error
4.1.7 Final estimates adjusted temperature
We integrated the autocorrelated error into our temperature estimates to generate a more refined model of temperature estimation. With this data in place, we transformed our wide-format data into a long-format data frame. Each row of this data frame represented a specific day from a specific year, containing information on the date, observed temperature, estimated temperature, error, and the adjusted estimated temperature (estimate + error).
This transformed format provided us with a holistic and granular view of our data, suitable for subsequent detailed analyses. Once the transformation was complete, the data was saved into a CSV file, enabling easy access for further research or data visualization tasks.
Above code will produce output previews like below.

Table 7. Final adjusted temperature
4.2 Jupyter Notebook
The provided code shows the process on how we can use monthly temperature data to generate daily time series temperature using Fourier regression models. Here’s a summary of what each part of the code does: https://gist.github.com/bennyistanto/a9e6045a78b230dbd5c443a0e0e4fa41
5 Results
The graphical visualization of the estimated daily temperature against the observed temperature provided a robust means of evaluating the efficacy of the Fourier model across the study period (1986-2021) at the Bogor Climatological Station. The estimated temperature, generated from the Fourier model, was superimposed onto a scatter plot of the observed temperatures. The latter were smoothed using the nonparametric LOESS technique to discern major trends within the data.
Each subplot delineated a separate year’s worth of data, allowing for an insightful year-to-year examination of the model’s performance. The observed temperatures were presented as scatter points, with the LOESS smoothing line capturing the general pattern of the temperature across different days of the year.
The comparison between the observed temperature trends and the estimates from the Fourier model revealed a substantial degree of congruence, indicating the model’s reliability in predicting daily temperature patterns. The Fourier model demonstrated a commendable ability to generate daily temperature estimates from monthly data. This affirms the model’s utility in climatological studies, particularly when granular daily data are not readily available.
Above code will produce a chart visualization below
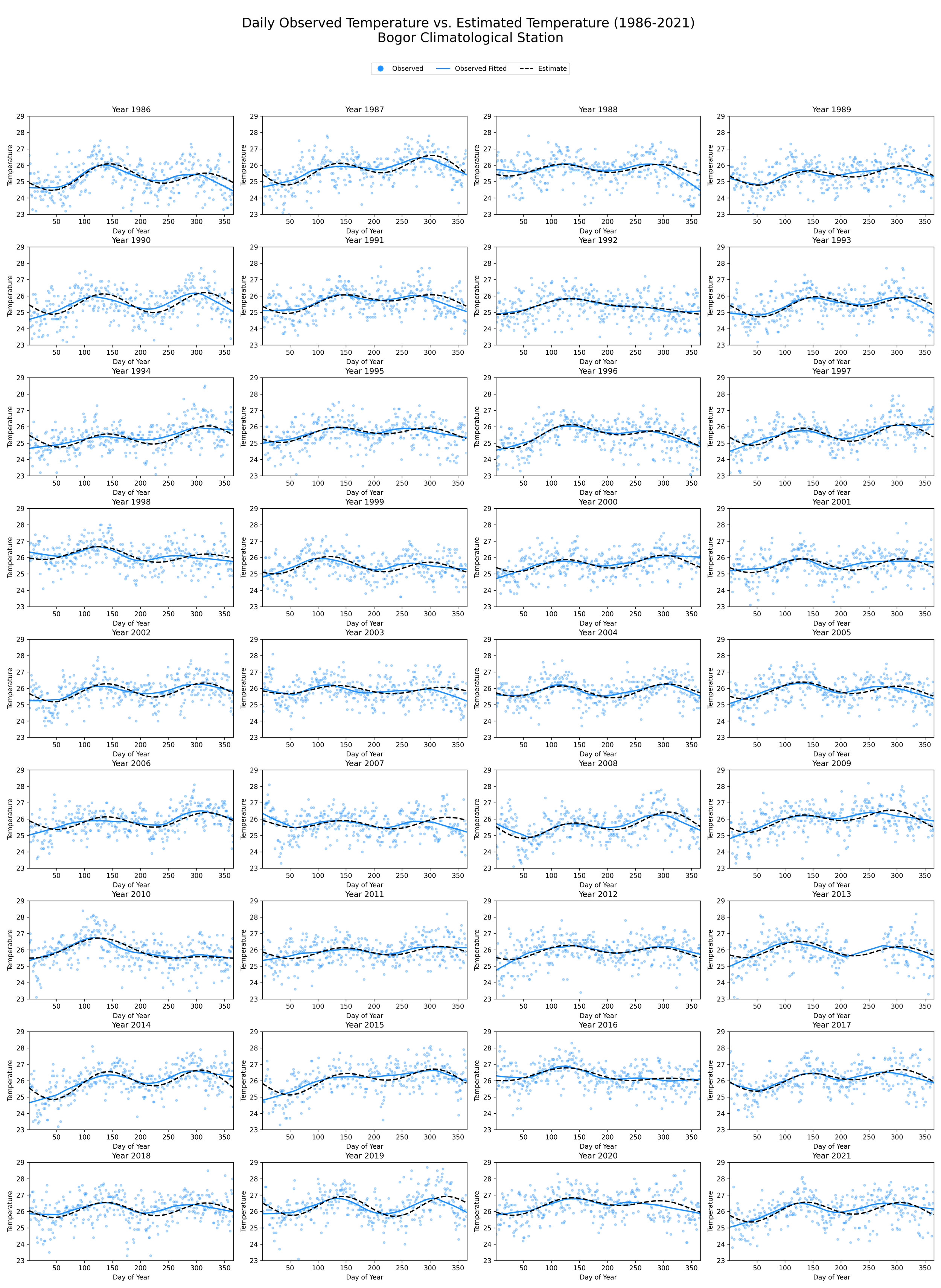
Picture 1. Observed temperature vs Estimated temperature, year-by-year
In this exercise, we implemented a method to compute autocorrelated errors between observed and estimated temperatures from 1986 to 2022. We began by loading our dataset, after which we defined an autocorrelation factor, a parameter that reveals the correlation between different points in time within the error series.
Each year’s temperature discrepancy was calculated and white noise, a random sequence derived from a normal distribution, was added. We then introduced the autocorrelation factor into the errors, with the first day’s error being only the white noise. The error for subsequent days factored in both the white noise and a portion of the previous day’s error, weighted by the autocorrelation factor.
Post computation, we organized the autocorrelated errors into a dictionary, subsequently transforming it into a DataFrame for further analysis. This dataset of autocorrelated errors presents the unexplained variance within our model, potentially stemming from unaccounted factors such as climate changes or certain atmospheric conditions.
Finally, we integrated these autocorrelated errors with our estimated temperatures, resulting in an adjusted and more refined temperature prediction. This revised dataset was then visualized in a time series plot, allowing for a comparative analysis between observed and adjusted estimated temperatures. The plot revealed a clear upward trend in the temperature at the Bogor Climatological Station from 1986 to 2021. Notably, the application of autocorrelated errors offered an excellent fit to the observed temperatures, thus affirming the effectiveness of our model.
Above code will produce a chart visualization below
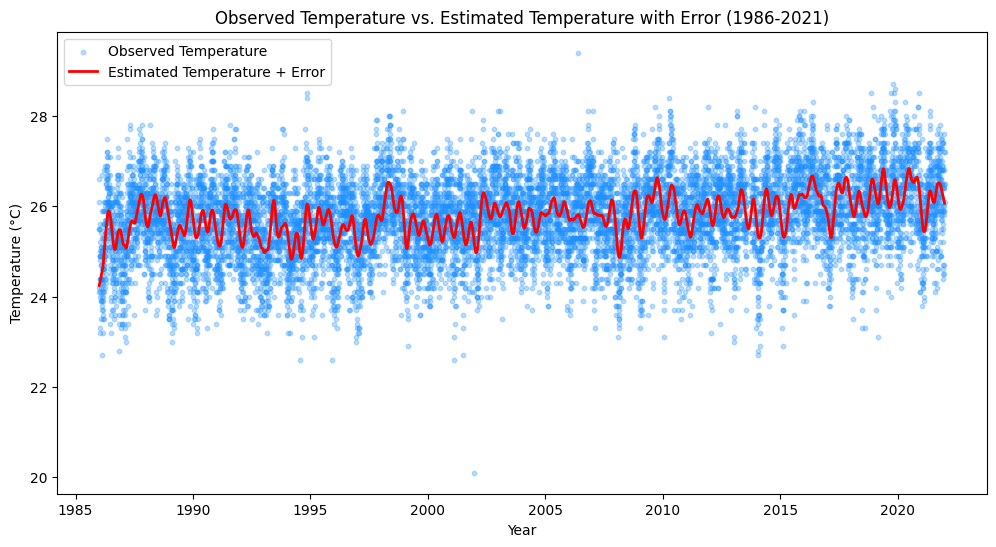
Picture 2. Observed temperature vs Estimated temperature with error
The Fourier model’s estimates were further scrutinized by integrating autocorrelated errors into the calculations. This facilitated the generation of a modified temperature prediction that comprised the original estimate and the error. Upon examination, the plots vividly displayed a comprehensive juxtaposition of this adjusted forecast against the observed data for each year from 1986 to 2021.
Notably, the error-adjusted estimates, visualized through LOESS-smoothed lines, revealed minor disparities compared to the original model predictions. These charts underscored the pertinence of accommodating inherent model errors and substantiated the robustness of the Fourier model’s initial estimates. The insights derived from this comparison can guide further refinements to the model for superior accuracy in future temperature estimates.
Above code will produce a chart visualization below
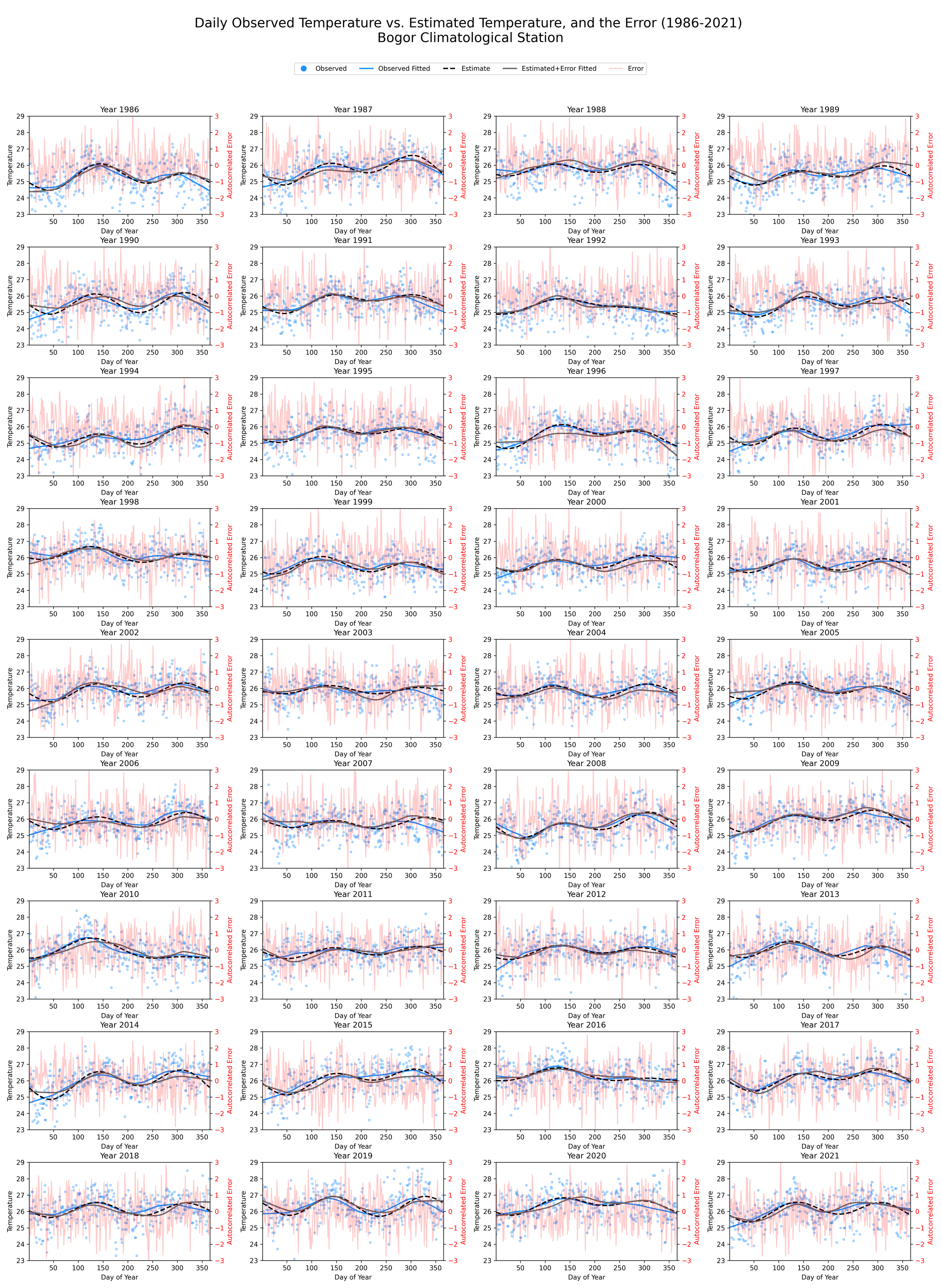
Picture 3. Observed temperature vs Estimated temperature with error, year-by-year
6 Conclusion
The application of the Fourier regression model for generating daily time series data from monthly temperature observations has demonstrated considerable efficacy in climatological studies. This modeling approach provides a mathematically rigorous way to interpolate intra-monthly fluctuations, leveraging periodicity inherent in annual temperature patterns. The model is thus capable of filling data gaps and offering granular insights into day-to-day temperature variations, a granularity that monthly data alone cannot provide.
Notably, the model’s provision for the autocorrelation of errors adds an additional layer of realism to the estimations, acknowledging the dependence of errors on preceding values. This factor makes the model responsive to the serial correlation often seen in climatic data, enhancing its predictive capabilities.
In conclusion, Fourier regression modeling serves as an invaluable tool for climatologists, offering an effective means of generating daily time series data from sparse or aggregated observations. Through its utilization, it is possible to acquire more detailed insights into temperature dynamics, paving the way for refined climate studies, policy formulation, and mitigation strategies against climatic anomalies. The model’s robustness, flexibility, and accommodating nature towards error correlation further enhance its applicability, making it a staple in the data-driven examination of climate patterns.
7 References
Epstein, E.S. 1991. On Obtaining daily climatological values from monthly means. J. Climate 4:465-368. https://doi.org/10.1175/1520-0442(1991)004%3C0365:OODCVF%3E2.0.CO;2
Boer, R., Notodipuro, K.A., Las, I. 1999. Prediction of Daily Rainfall Characteristics from Monthly Climate Indices. RUT-IV report. National Research Council, Indonesia.
Castañeda-Miranda, A., Icaza-Herrera, M. de, & Castaño, V. M. (2019). Meteorological Temperature and Humidity Prediction from Fourier-Statistical Analysis of Hourly Data. Advances in Meteorology, 2019, 1–13. https://doi.org/10.1155/2019/4164097
Hernández-Bedolla, J.; Solera, A.; Paredes-Arquiola, J.; Sanchez-Quispe, S.T.; Domínguez-Sánchez, C. A Continuous Multisite Multivariate Generator for Daily Temperature Conditioned by Precipitation Occurrence. Water 2022, 14, 3494. https://doi.org/10.3390/w14213494
McCaskill, M.R. 1990. An efficient method for generation of full climatological records from daily rainfall. Australian Journal of Agricultural Research 41, 595-602. https://doi.org/10.1071/AR9900595
Parra-Plazas, J., Gaona-Garcia, P. & Plazas-Nossa, L. Time series outlier removal and imputing methods based on Colombian weather stations data. Environ Sci Pollut Res 30, 72319–72335 (2023). https://doi.org/10.1007/s11356-023-27176-x
Srikanthan, R., & McMahon, T. A. (2001). Stochastic generation of annual, monthly and daily climate data: A review. Hydrology and Earth System Sciences Discussions, 5(4), 653-670. https://doi.org/10.5194/hess-5-653-2001
Stern, R. D., & Coe, R. (1984). A model fitting analysis of daily rainfall data. Journal of the Royal Statistical Society. Series A (General), 147(1), 1-34. https://doi.org/10.2307/2981736
Wannacott, T.H. abd R.J. Wannacott. 1987. Regression: A second course in statistics. Robert E. Krieger Publishing, Co. Florida.