Regression analysis with dummy variables
This exercise aims to determine the best reduced model (RM) in regression analysis with dummy variables from annual rainfall data and altitude data in three different regions. This will result in a new regression equation capable of describing the relationship between altitude and rainfall in these three regions.
Summary
The dummy variables constructed in this article are based on regional location, specifically regions 1, 2, and 3. The initial analysis entailed the representation of data for each region through scatter plots. Thereafter, a regression analysis with all parameters was conducted to derive the Full Model (FM). Subsequently, the scatter plot patterns for each region were examined, and regression equation models with identical intercepts or slopes were identified. The objective was to generate simpler regression models or equations (Reduced Models - RM) from the dummy variables constructed based on regional location. Upon obtaining several RMs, all were statistically tested using the F-test to ascertain their similarity to the FM. It was also necessary to compute and analyze the Mallows’s Cp value for all RMs to determine the optimal RM. A good Reduced Model is one that is similar or identical to the Full Model. The F-test performed in this report was designed to determine whether the RM is similar or identical to the FM. The hypotheses for the F-test were as follows.
H0: FM = RM
H1: FM ≠ RM
The null hypothesis is refuted in instances where the observed F-value surpasses the F-table value. This suggests that, as of yet, there’s insufficient robust evidence to proclaim that the Reduced Model (RM) bears resemblance to the Full Model (FM) (Kutner et al., 2005). Within the conducted F-test analysis, a confidence interval of 95% is employed. The observed F-value can be calculated using the following formulation (Kutner et al., 2005):
\[F_{\text{Observed}} = \frac{(SSR_{FM} - SSR_{RM})/(df_{R,FM} - df_{R,RM})}{SSE_{FM}/df_{E,FM}}\]
The F-table value is derived from the F-distribution with the calculated degrees of freedom
\[F_{\text{table}} = F(df_{R,FM} - df_{R,RM}, df_{E,FM})\]
The RM is considered as efficient or akin to the FM if the Mallows’s Cp value is equal to or less than the total number of parameters (\(C_{P,\text{Mallows}} \leq p\)) (Mallows, 1973). The Cp value is determined using the equation:
\[C_{P,\text{Mallows}} = p + \frac{(S^2 - \sigma^2)(n - p)}{\sigma^2}\]
where \(p\) represents the number of parameters utilized in the RM, \(n\) denotes the total number of observations within the model (\(n=45\)), \(S^2\) is the variance of the RM, and \(\sigma^2\) is the variance of the FM.
Data
Total rainfall in different altitude and region. The data available in csv format with columns: altitude; rainfall; region
The data for this analysis is available from this link: https://drive.google.com/file/d/1v3CGHBykg3UUqjKS3oyy8rIGsogN1DY5/view?usp=sharing
Implementation
In the implementation phase of this analysis, we utilized Python and the library to develop dummy variables regression
Plot the input data
The code presented aims to investigate the relationship between rainfall and altitude across different regions. The dataset, obtained from a CSV file, contains information on rainfall and altitude for various regions. The code utilizes the pandas library to read the data and matplotlib and seaborn libraries for data visualization.
To begin, unique regions in the dataset are identified. A dictionary, regression_params, is created to store the coefficients of the regression equations for each region. Subsequently, a scatter plot is generated for each region, where altitude is plotted on the x-axis and rainfall on the y-axis. This is achieved using the sns.scatterplot function from the seaborn library.
A linear regression model is then fitted to the data for each region using the LinearRegression class from the sklearn.linear_model module. The model is trained with altitude as the predictor variable (X) and rainfall as the target variable (y). The slope and intercept coefficients of the regression equation are obtained from the fitted model.
The regression coefficients are stored in the regression_params dictionary, associating them with their respective regions. Additionally, the regression equation is displayed on the plot for each region using the ax.text function. A regression line is drawn on the plot using the ax.plot function to visualize the relationship between altitude and rainfall.
The resulting plot showcases the rainfall-altitude relationship for different regions, with each region’s data points, regression line, and equation displayed. The plot is saved as an image file, and the figure is displayed for further examination.
Finally, the regression parameters for each region are printed to provide insights into the specific regression equations obtained. The slope and intercept values are extracted from the regression_params dictionary and displayed for each region.
 [caption id=“” align=“alignnone” width=“1920”]
[caption id=“” align=“alignnone” width=“1920”]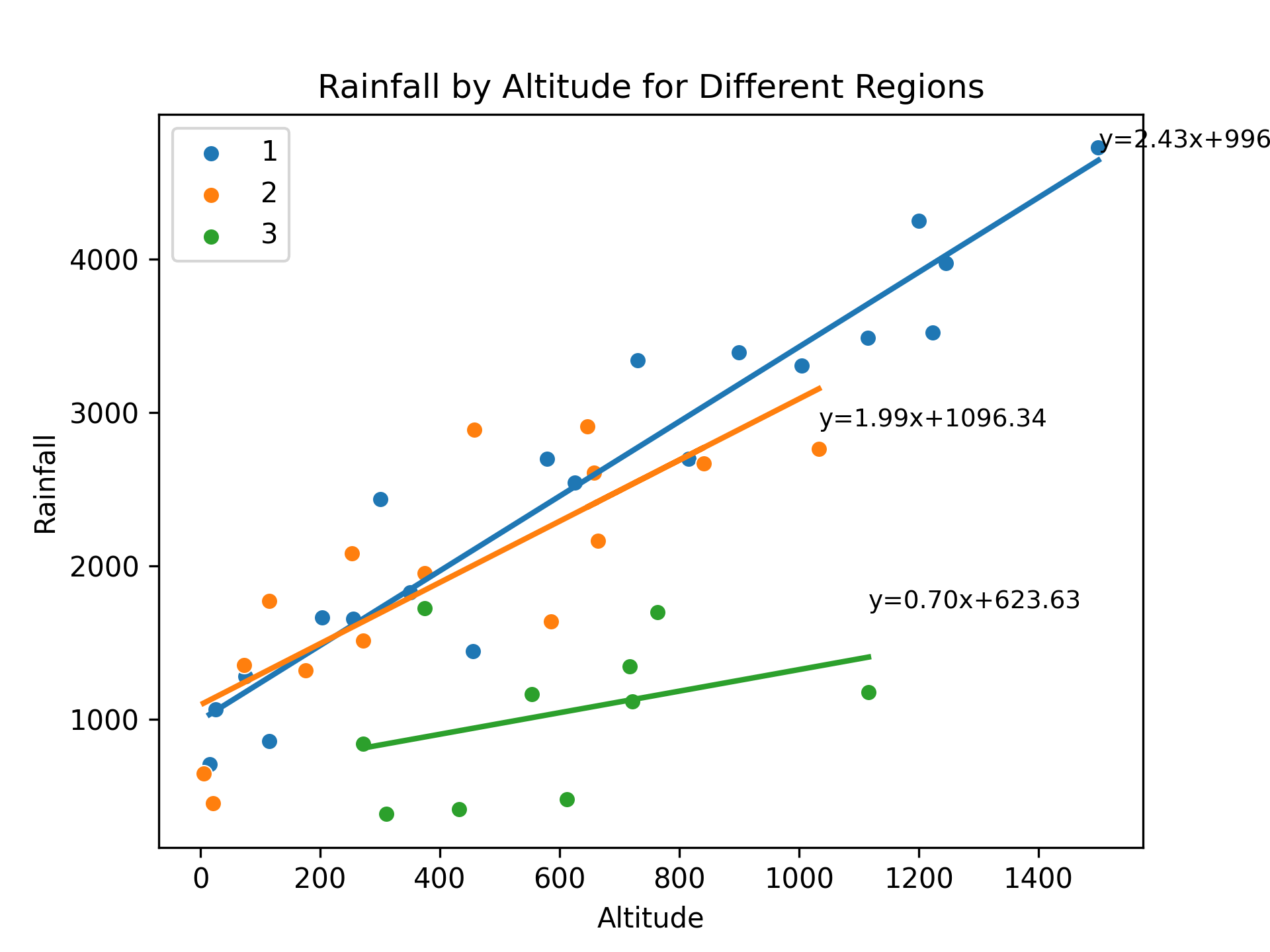 For region 1, the regression equation is y = 2.43x + 996.53 For region 2, the regression equation is y = 1.99x + 1096.34 For region 3, the regression equation is y = 0.70x + 623.63 [/caption]
For region 1, the regression equation is y = 2.43x + 996.53 For region 2, the regression equation is y = 1.99x + 1096.34 For region 3, the regression equation is y = 0.70x + 623.63 [/caption]
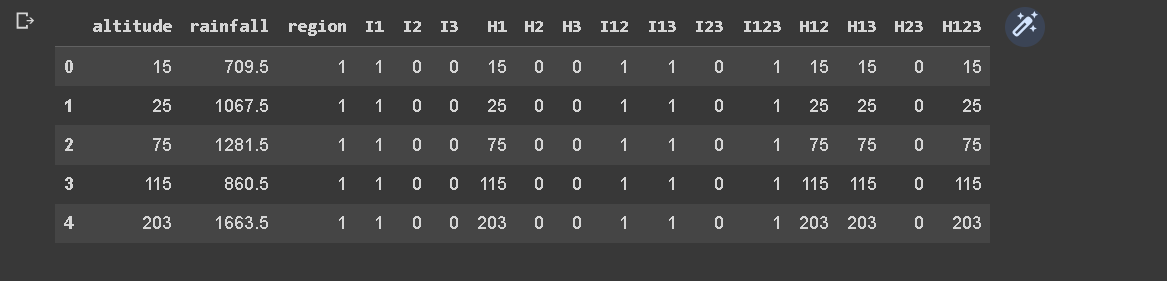
The provided code snippet focuses on data preprocessing and feature creation based on the information in a CSV file. It employs the pandas library for data manipulation and transformation.
Initially, the CSV file is read into a DataFrame using the pd.read_csv function, with the resulting DataFrame stored as df.
Next, several new columns are created based on the region column. These new columns serve as indicator variables to represent different regions in the dataset. Specifically, columns I1, I2, and I3 are generated using logical comparisons to check if the region value matches the respective region number. The astype(int) method is then applied to convert the resulting Boolean values to integers.
Similarly, additional columns H1, H2, and H3 are created by multiplying the altitude column with the corresponding indicator variables (I1, I2, and I3). This results in the creation of separate altitude columns for each region, where the altitude values are present only for the respective region and are set to zero for other regions.
Following this, combinations of indicator variables are generated to represent different combinations of regions. Columns I12, I13, I23, and I123 are created using logical comparisons to check if the region value matches the respective region combination. Column I123 is assigned a constant value of 1 since it represents the inclusion of all regions.
Similarly, new altitude columns H12, H13, H23, and H123 are created by multiplying the altitude column with the respective combination indicator variables. These columns enable the representation of altitude values for specific region combinations.
Lastly, the modified DataFrame is saved as a new CSV file using the to_csv function, with the file path specified and the separator set to ;. The resulting DataFrame is displayed using the df.head() method to show the first few rows of the transformed dataset.
In summary, this code segment demonstrates a data preprocessing step where new columns are created to represent regions and region combinations based on the original data. These transformations facilitate subsequent analysis and modeling tasks by providing a more informative and structured dataset.
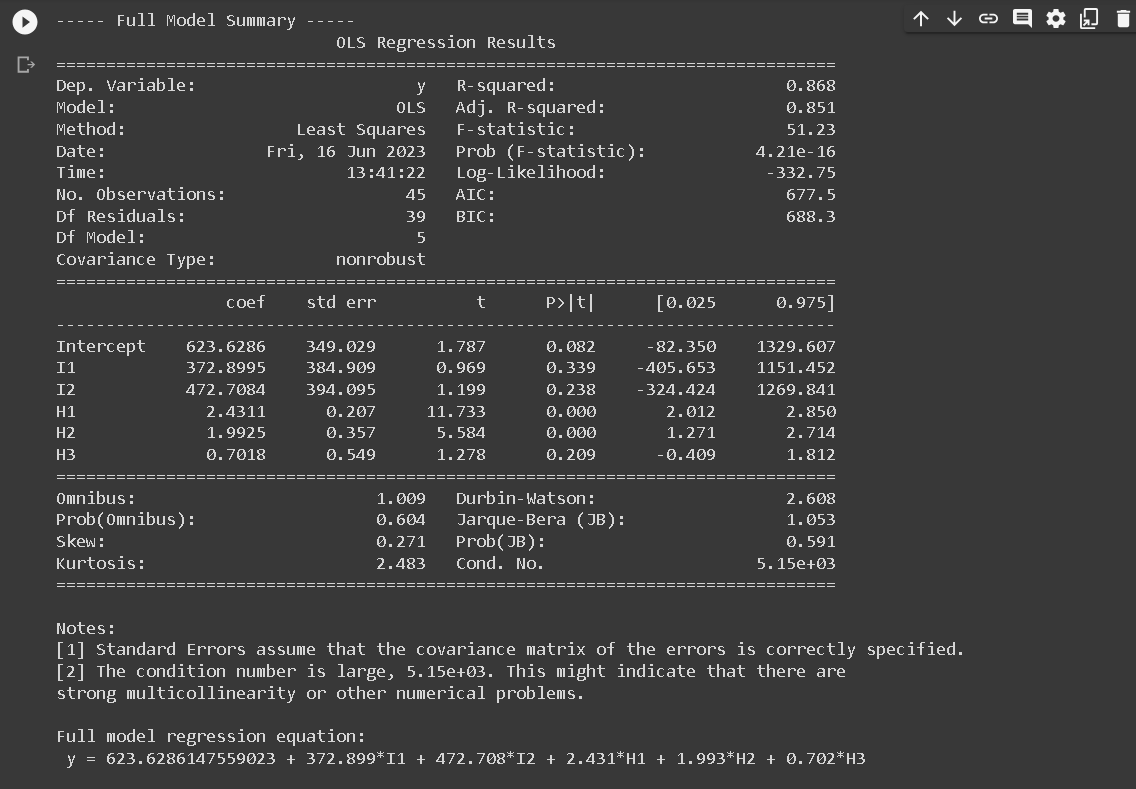
Full model, avoid dummy trap
The Full Model regression equation doesn’t include I3 because of a technique used in regression analysis known as dummy coding. When we have a categorical variable with k levels (in this case, region with 3 levels), we need to create k-1 dummy variables to represent it in the regression model.
The reason for using k-1 dummy variables instead of k is to avoid the dummy variable trap, which is a scenario in which the independent variables are multicollinear. In other words, one variable can be predicted perfectly from the others.
In our case, I1, I2, and I3 represent the three regions. If we included all three in our model, we would have perfect multicollinearity because I3 can be perfectly predicted from I1 and I2 (if I1 = 0 and I2 = 0, then I3 has to be 1). This would make the model’s estimates unstable and uninterpretable.
By leaving out I3, we are implicitly choosing region 3 as the reference category. The coefficients for I1 and I2 then represent the difference in the outcome between regions 1 and 3, and regions 2 and 3, respectively.
If we want to make comparisons between regions 1 and 2, we can either change the reference category (by including I3 and leaving out I1 or I2 instead), or compute the difference between the I1 and I2 coefficients.
Reduced Model
Next, we are talking about creating Reduced Models (RMs) from a Full Model (FM) with dummy variables representing regions and altitude variables interacted with these region dummies. The Full Model (FM) in this context is:
FM: y123 = a1 I1 + a2 I2 + a3 I3 + b1 H1 + b2 H2 + b3 H3
where:
- y123 represents rainfall
- I1, I2, I3 are dummy variables for regions 1, 2, and 3, respectively
- H1, H2, H3 are altitude variables interacted with the respective region dummies
Based on this FM, we can derive 5 different Reduced Models (RMs):
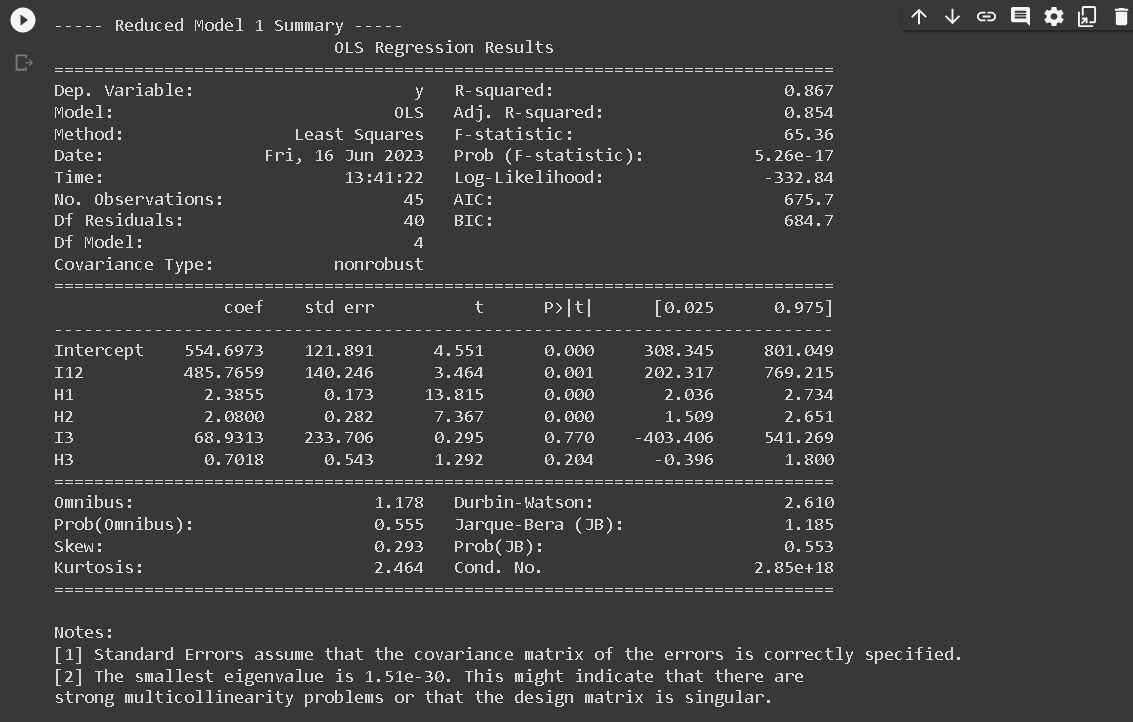
- RM1: Common slope across region 1 and region 2: y123 = a12 I12 + b1H1 + b2H2 + a3 I3 + b3H3
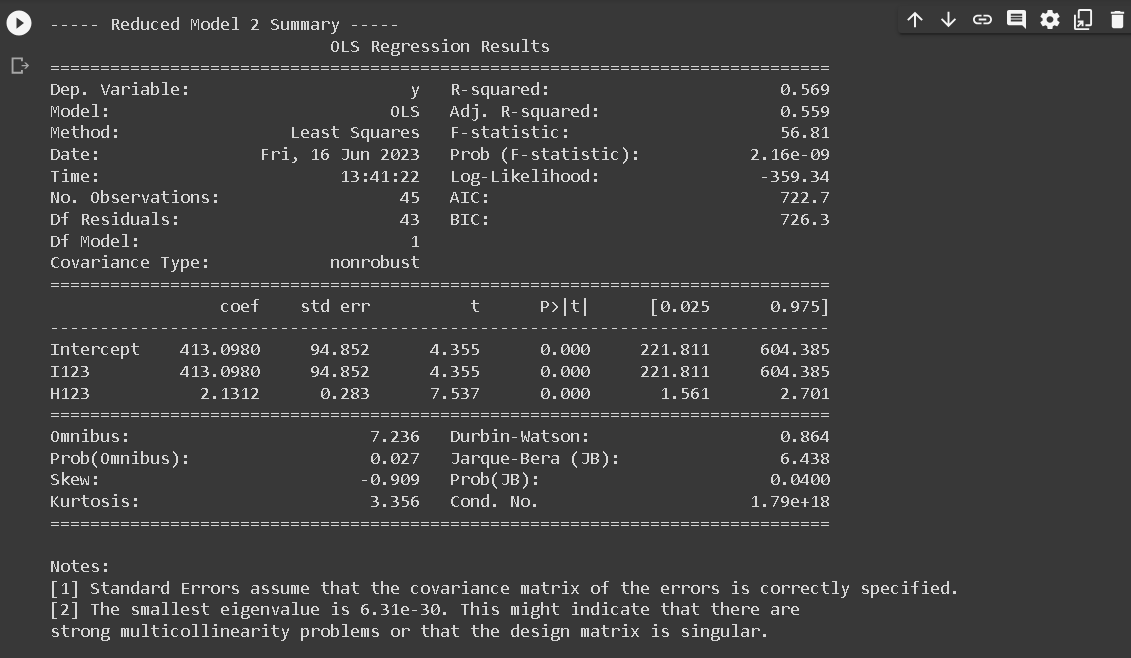
- RM2: Common intercept and slope across all regions: y123 = a123 I123 + b123 H123
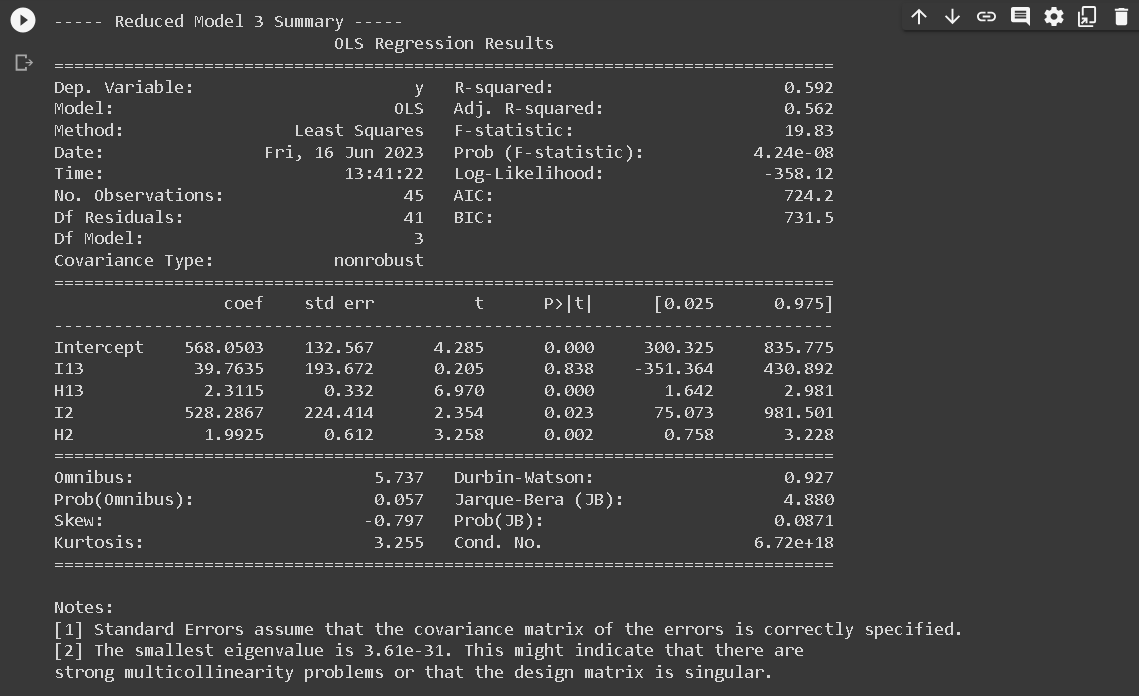
- RM3: Common intercept and slope across region 1 and region 3, different slope for region 2: y123 = a13 I13 + b13H13 + a2I2 + b2H2
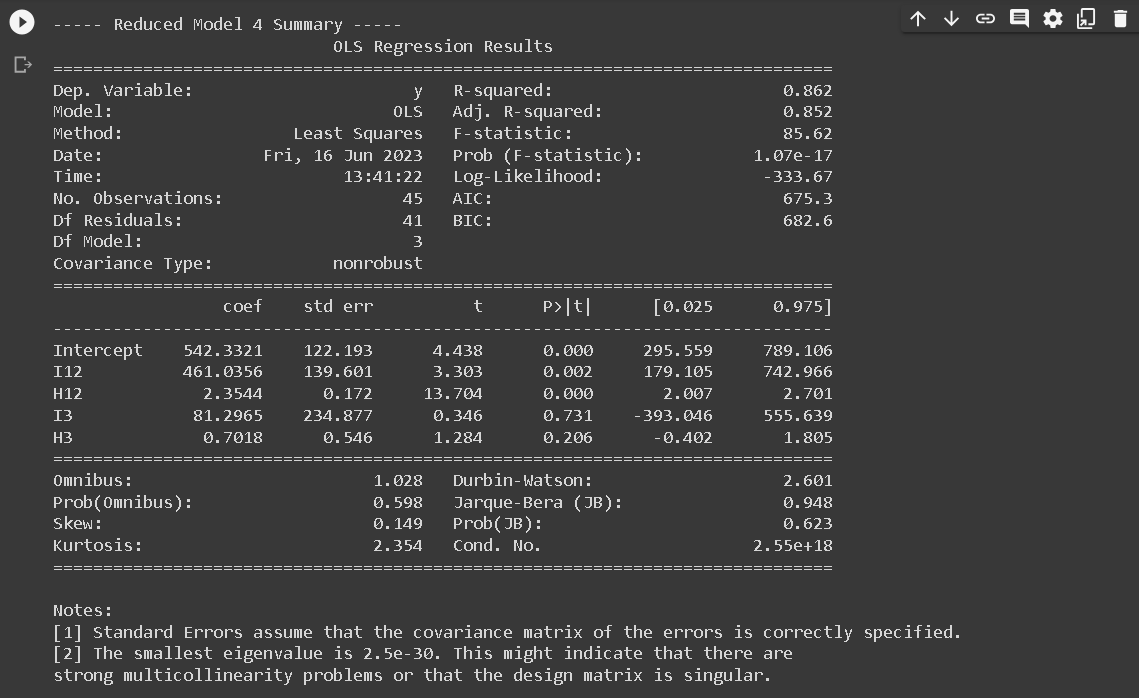
- RM4: Common slope across region 1 and region 2, different slope for region 3: y123 = a12 I12 + b12 H12 + a3I3 + b3H3
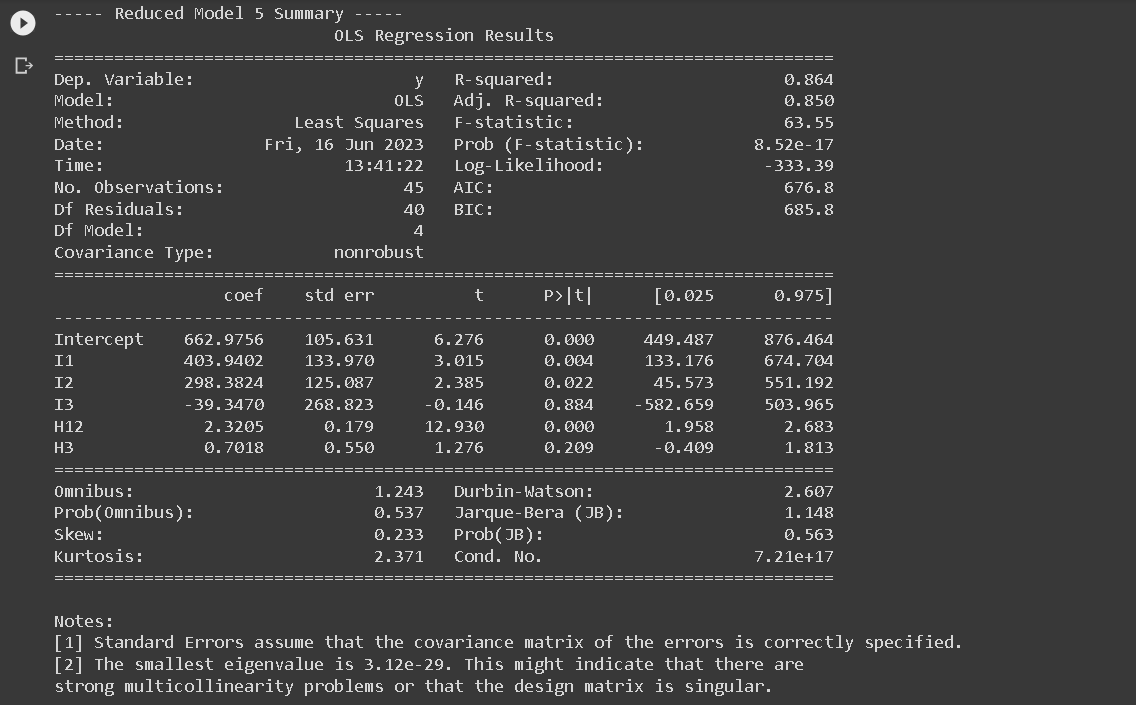
- RM5: Common intercept across all regions, common slope across region 1 and region 2, different slope for region 3: y123 = a1 I1 + a2 I2 + a3 I3 + b12 H12 + b3 H3
Cp Mallows
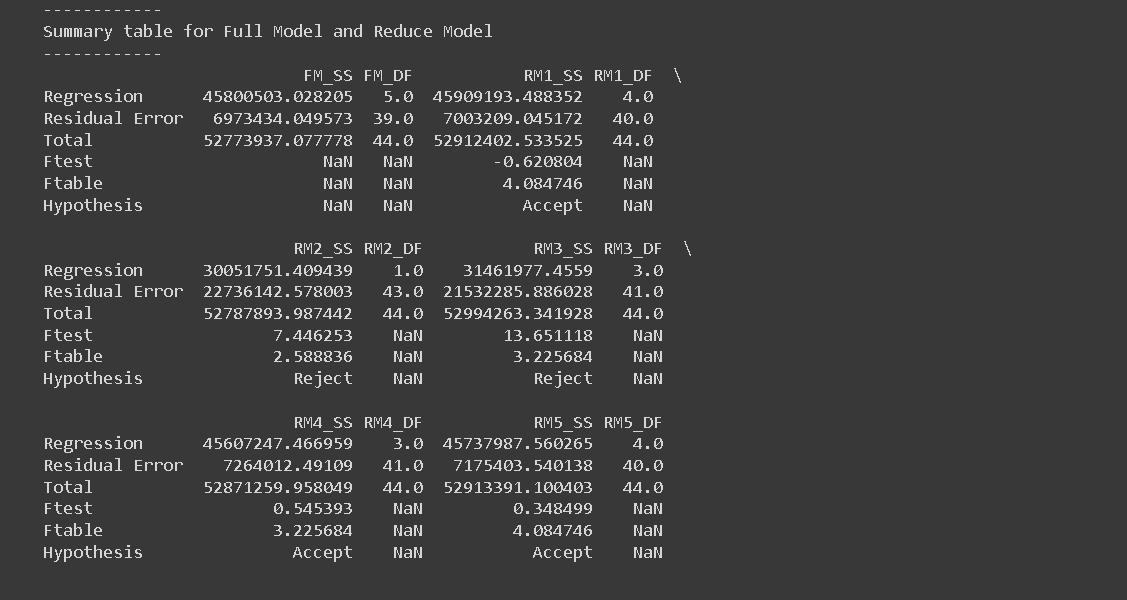
Next, a summary table was created to provide a succinct overview of both the Full Model (FM) and each Reduced Model (RM). This table is essential as it encapsulates vital statistical information about each model. This summary table consists of five columns: P, S, σ, n, and C_P_Mallow, and six rows corresponding to FM’,RM1,RM2’, RM3, RM4, and RM5.
The P denotes the number of parameters used in each model, S indicates the standard deviation of the residuals, σ represents the standard deviation of residuals for the full model, n signifies the number of observations, and C_P_Mallow represents the value of Mallow’s C_P statistic.
In the process of determining the effectiveness of the Reduced Models in relation to the Full Model, the Mallow’s \(C_P\) statistic plays a crucial role. According to Mallows (1973), a Reduced Model can be considered comparable to the Full Model if the Mallow’s \(C_P\) value is less than or equal to the number of parameters (\(C_{P,\text{Mallow}} \leq p\)). This statistic is calculated using the formula:
\[C_{P,\text{Mallow}} = p + \frac{(S^2 - \sigma^2)(n - p)}{\sigma^2}\]
In this context, \(p\) corresponds to the number of parameters used in the Reduced Model, \(n\) denotes the total data observations used in the model (in this case, \(n=45\)), \(S^2\) is the variance of the Reduced Model, and \(\sigma^2\) is the variance of the Full Model. By making use of this computation, we were able to evaluate the efficiency of each Reduced Model in comparison to the Full Model, aiding in the effective and accurate analysis of our data set.

Plot Cp Mallows
Based on the provided results from the code, we can create a plot to visualize the CP Mallow statistic. The x-axis of the plot will represent the number of predictors (P), while the y-axis will represent the CP Mallow values.
To begin, we will draw a cross line starting from the point (1, 1) and extending to the point (n, n), where ‘n’ represents the total number of observations. This line will serve as a reference and help us identify the region of interest.
Next, we will plot the CP values on the y-axis corresponding to the respective number of predictors (P) on the x-axis. Each point on the plot will represent a reduced model, with the CP value indicating its performance compared to the full model.
To highlight the specific point that satisfies the given criteria - the lowest number of predictors (P) and falls either above or below the cross line - we can customize the marker style or color for that point. This will make it visually distinct from the other points on the plot.
By examining the plot, we can easily identify the reduced model that strikes a balance between simplicity (fewer predictors) and predictive power (CP Mallow value). The highlighted point will represent the optimal reduced model that meets these criteria.
This plot provides a visual representation of the CP Mallow statistic, allowing us to compare the performance of different reduced models and select the most appropriate one based on the desired balance between complexity and prediction accuracy.
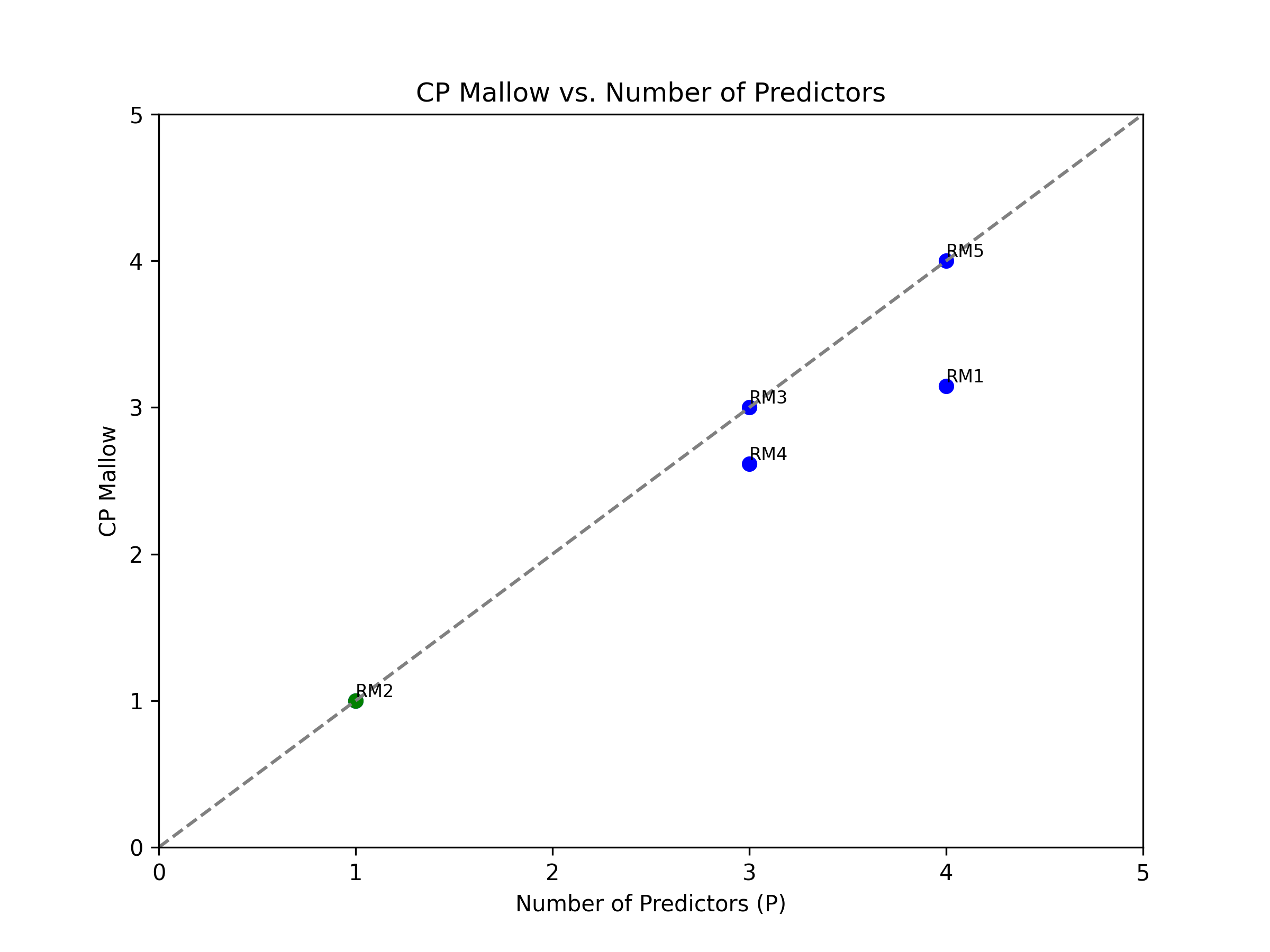
The execution of linear regression analysis across the three designated regions indicated a correlation between the augmentation of annual precipitation and escalating altitude. The reduced models (RM) that demonstrated a close correspondence to the full model (FM) were RM2 and RM4. However, the models that exhibited remarkable efficacy were RM2. The characteristics embodied by the first and second regions can be postulated to bear similarities, while they exhibit discernible divergence from the attributes of the third region